
Every industrial company accumulates documentation at a rate that far outpaces anyone’s ability to actually use it. Maintenance manuals, engineering schematics, commissioning procedures, safety protocols the knowledge exists, usually in abundance. The problem is access: finding the right piece of information, at the right moment, in a form that is actually usable by someone whose hands are occupied and whose attention is already stretched thin.
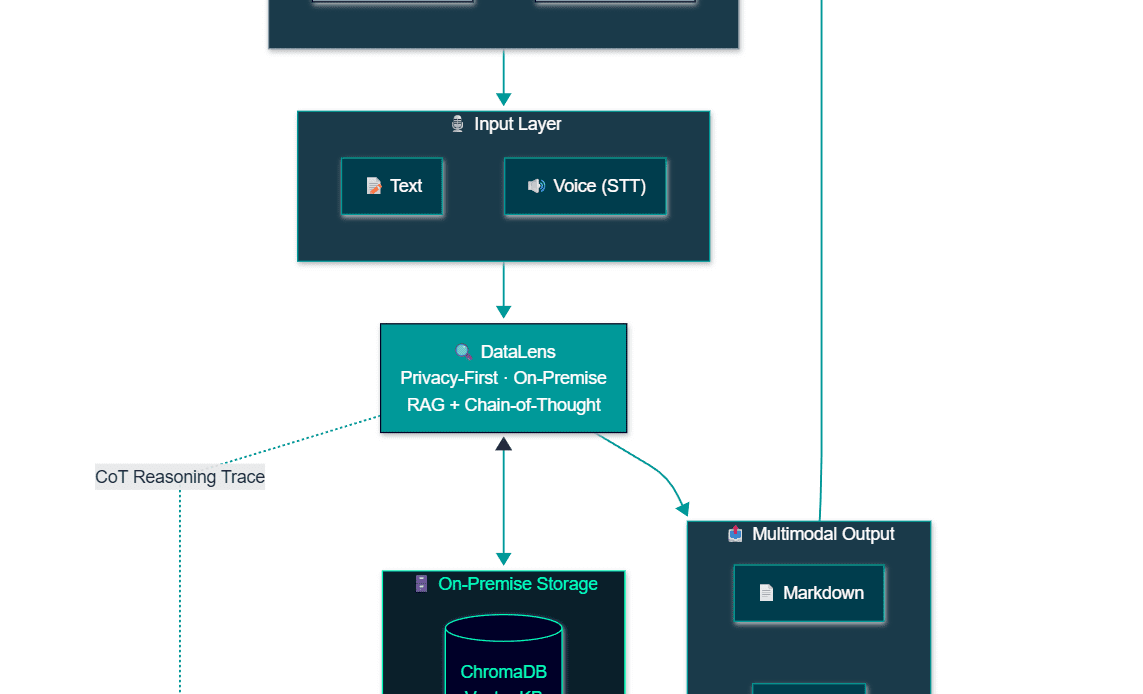
This is the problem that DataLens was built to address. Developed by Siemens (SIE), DataLens is a privacy-first, on-premise conversational AI framework that allows industrial operators to query their own technical documentation through natural language inside Extended Reality (XR) environments. It has been deployed in two distinct industrial pilots: a robotics commissioning context with KUKA, and an aircraft maintenance training programme with TAP Air Portugal. Both deployments offer useful lessons, not just about what the system can do, but about the conditions under which AI assistance in industrial settings actually earns the trust of the people using it.
DataLens Integration within XR5.0
The Privacy Constraint as a Design Driver
Before getting into what DataLens does, it is worth understanding why it was built the way it was. Most conversational AI products today rely on external cloud infrastructure queries leave the organisation, get processed somewhere else, and responses come back. For many consumer applications, that is an acceptable trade-off. For an aerospace maintenance company or a robotics manufacturer with proprietary engineering documentation, it is not.
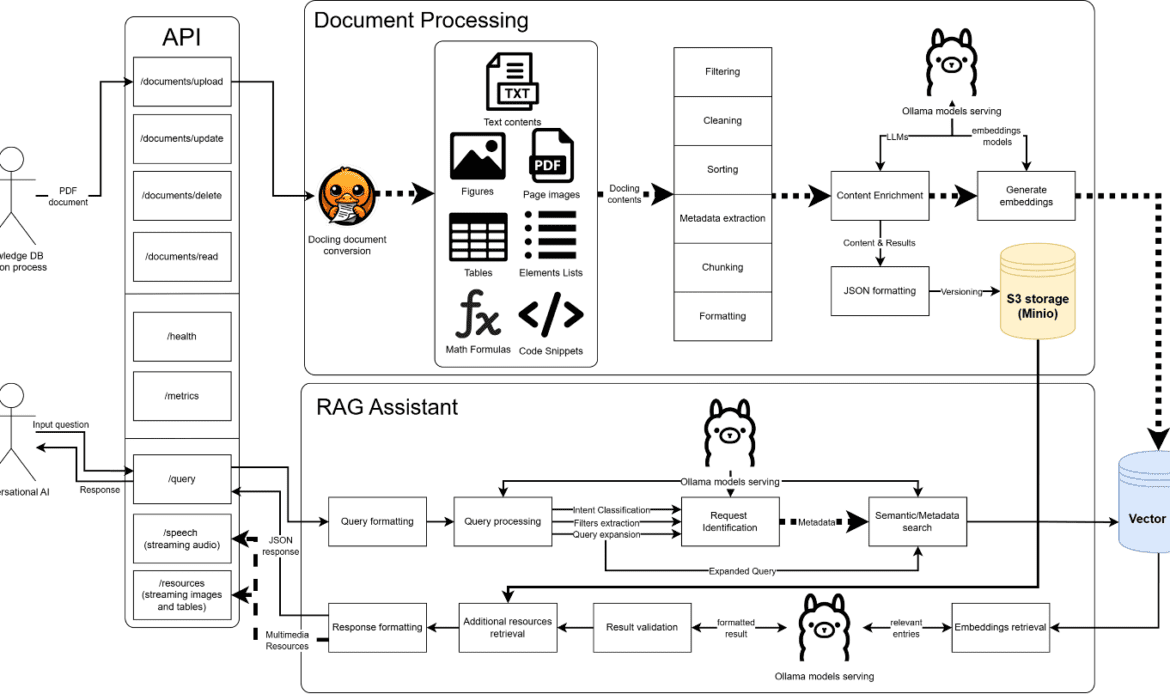
DataLens runs entirely on private cloud instances. No data leaves the organisation’s infrastructure. This is not simply a compliance checkbox it is the architectural foundation from which everything else follows. The system is built on open-source components precisely because they can be audited, deployed locally, and operated without dependency on any external service provider. The stack includes Ollama for serving locally-running language models, Docling for structured PDF extraction, MinIO for document and image storage, and ChromaDB for managing the vector-based knowledge bases that power semantic search.
The result is a system that organisations can actually trust with sensitive documentation which, in turn, is what makes the conversational AI layer meaningful. An assistant that cannot be trusted with the documents is not much of an assistant.
DataLens High Lever Architecture
What the System Actually Does
DataLens is structured around two core components. The first is a document processing pipeline that ingests PDF documents, extracts their content in structured form text, tables, images, metadata and commits everything to a vector database through an embedding process. The second is a Retrieval-Augmented Generation (RAG) assistant that accepts user queries, classifies their intent, expands them where necessary, retrieves semantically relevant content from the knowledge base, and generates a structured response.
The system accepts both text and voice input, which matters considerably in XR contexts where typing is not a realistic interaction mode. Responses are multimodal: formatted text, synthesised audio, optional reference images, and source metadata indicating exactly which document and section the answer came from.
The API layer sits above all of this, exposing a versioned REST interface that allows the system to be integrated into any external application including XR headset environments without requiring the consuming application to know anything about the underlying AI infrastructure.
The Harder Problem: Trust and Explainability
Retrieving a relevant document chunk and presenting it as an answer is, technically speaking, not that difficult. The harder problem is giving the person receiving that answer a reason to trust it and, when they should not trust it, a way to know that.
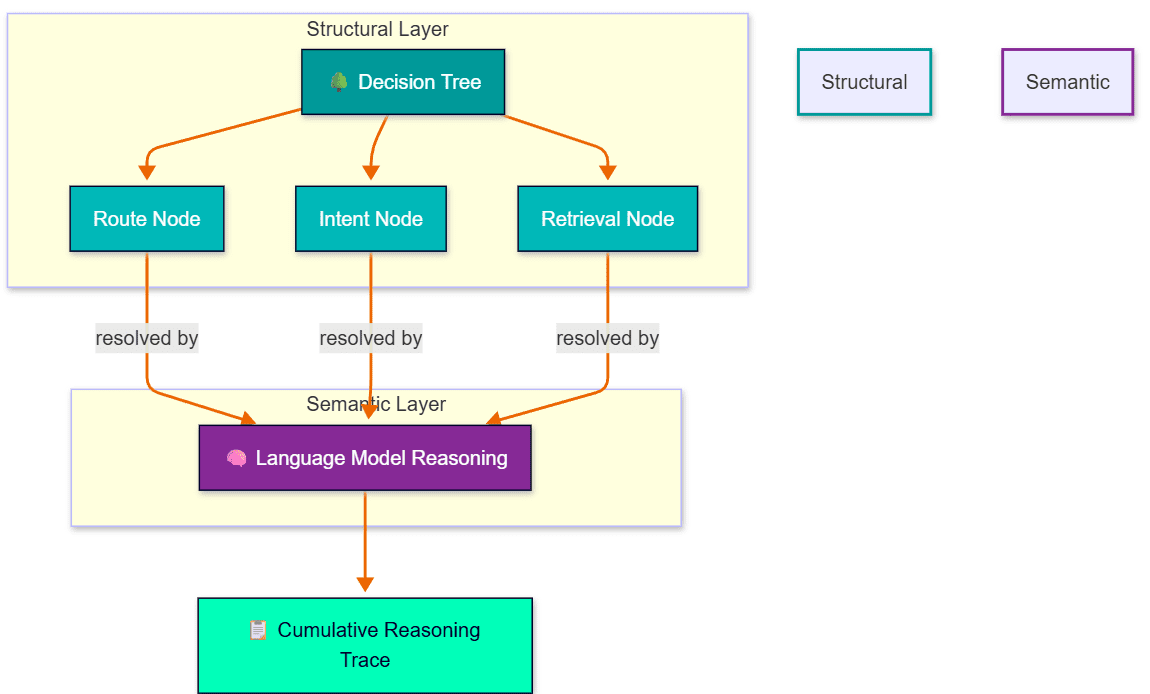
This is where DataLens goes beyond being a search interface. The system incorporates Chain-of-Thought (CoT) reasoning as its primary mechanism for explainability. Rather than routing a query through a single model call and returning whatever comes out, the pipeline decomposes query resolution into a sequence of discrete, auditable stages. Each stage has a specific responsibility: route classification, intent resolution, query expansion, retrieval, response generation. At every stage, the reasoning produced by the language model is captured and appended to a cumulative reasoning trace, which is returned alongside the final answer as a dedicated field in the API response.
The practical effect is that the system’s decision path from the user’s original query to the generated response is fully visible. A human operator, or a downstream application, can inspect exactly how the system interpreted the query, what it retrieved, and why it generated the response it did. This is not a minor feature. In environments where AI-generated guidance may inform safety-critical decisions, the ability to trace a response back through its reasoning chain is an operational necessity, not an optional transparency enhancement.
The pipeline’s design is also directly aligned with Articles 13 and 14 of the EU AI Act, which mandate transparency and human oversight for high-risk AI systems. The structured JSON outputs and multi-stage reasoning architecture ensure that every response can be audited, attributed to its source, and reviewed by a human operator.
Internally, the CoT implementation combines two complementary layers. The first is a system-defined decision tree a deterministic structure that routes queries through a predictable sequence of specialised prompts and metadata filters. The second is the language model’s own reasoning mechanism, which resolves each node of the decision tree and produces fine-grained semantic reasoning at every inference step. Together, these layers make the system’s behaviour both structurally auditable and semantically interpretable. All pipeline configuration route definitions, intent classifiers, system prompts, and model parameters is centralised in a single rag_runtime.yaml file, which simplifies debugging and makes extending the system with new query types a contained operation.
DataLens xAI Reasoning report
Pilot 1 — KUKA: Starting with Robotics
The first real-world deployment of DataLens happened within KUKA’s pilot, focused on virtual commissioning and generative AI in robotics. DataLens was deployed here as KUKABot, a conversational knowledge assistant built on top of a dedicated knowledge base populated with KUKA’s internal technical manuals equipment datasheets, operating manuals, and electrical design schematics, five documents in total.
Operators interacted with the system through a natural language interface inside an XR application, querying component specifications and commissioning procedures. The system handled documents navigation, summarisation, question and answer, content lookup, and comparisons 40 recorded interactions across the pilot evaluation. Retrieval performance was strongest for queries that used explicit technical terminology, where the vector similarity search consistently surfaced relevant entries.
Pilot 4 — TAP Air Portugal: Aircraft Maintenance Training
The second deployment moved DataLens into aircraft maintenance training, which represents a considerably higher-stakes environment. Aircraft Maintenance Technicians work with complex, safety-critical procedures where the cost of an error is not measured in downtime but in airworthiness. The pilot focused on training procedures related to the Wing Anti-Ice Valve (WAIV).
In this context, DataLens was deployed alongside the XR-Enabled AI Assistant an enterprise platform providing speech-to-text, text-to-speech, and conversational AI capabilities through a unified API. The two components form an integrated voice-driven pipeline: the XR-Enabled AI Assistant handles audio capture, transcription, and speech synthesis, while DataLens serves as the document intelligence layer, retrieving contextually relevant information from the ingested knowledge base and grounding every response in verified source documentation.
Technicians interacted with the system through voice and gesture, submitting queries such as “What are the steps involved in the WAIV installation?” The system processed the voice input, forwarded the transcribed query to the DataLens retrieval engine, and returned a response both in text and synthesised audio derived from the ingested technical documentation.
What the Evaluation Actually Showed
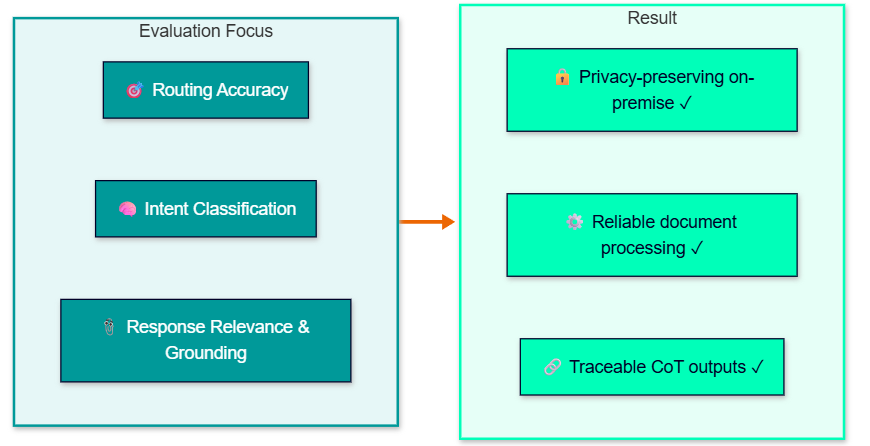
Across both pilots, evaluation confirmed the technical viability of the system as a privacy-preserving, on-premise conversational AI solution for industrial document querying. The document processing pipeline performed reliably on well-formed, born-digital technical documentation. The multimodal response format combining synthesised speech, formatted content, and source references was well received in both operational contexts.
The CoT pipeline evaluation focused on conversational routing accuracy, intent classification correctness, and the relevance and grounding of generated responses against their source documentation. The CoT structure consistently produced more reliable and traceable outputs than earlier single-prompt approaches, with the reasoning trace providing a transparent basis for identifying and correcting failure cases during iterative refinement.
DataLens Evaluation and Results
A Broader Point About Industrial AI
The lessons from DataLens extend beyond the specifics of the framework. The transition from a single-prompt architecture to a structured CoT pipeline demonstrated that explainability and reliability in RAG systems are best achieved through deliberate decomposition of the reasoning process, not through reliance on model capability alone. The model evaluation process reinforced that raw reasoning capability does not necessarily translate to pipeline suitability stability, predictability, and token efficiency are equally critical selection criteria when deploying language models within structured conversational workflows.
More broadly, the pilot deployments confirmed something that is easy to understate: architectural decisions need to be grounded in real operational feedback. The version of DataLens that exists after two pilots is substantially different from the version that entered them, and that evolution was driven by what actually happened when real users, in real environments, tried to use the system to do real work.
That, in the end, is probably the most transferable lesson. AI systems for industrial use do not arrive fully formed. They are shaped sometimes significantly by the gap between what designers anticipate and what operators actually need.